Importare dati in pandas da un file .csv
Questo argomento è un approfondimento di una micro-lezione proposta da analiticas, la newsletter di micro-lezioni per imparare ad analizzare i dati con Python.
Utilizzare Python e la libreria pandas per analizzare dati prevede un banale requisito: i dati! Da dove li prendiamo? Dove li importiamo? Cosa ne facciamo?
I dati che andremo ad importare nel nostro script andranno a costituire un dataframe (spesso abbreviato come df) che ha grosso modo questo aspetto:
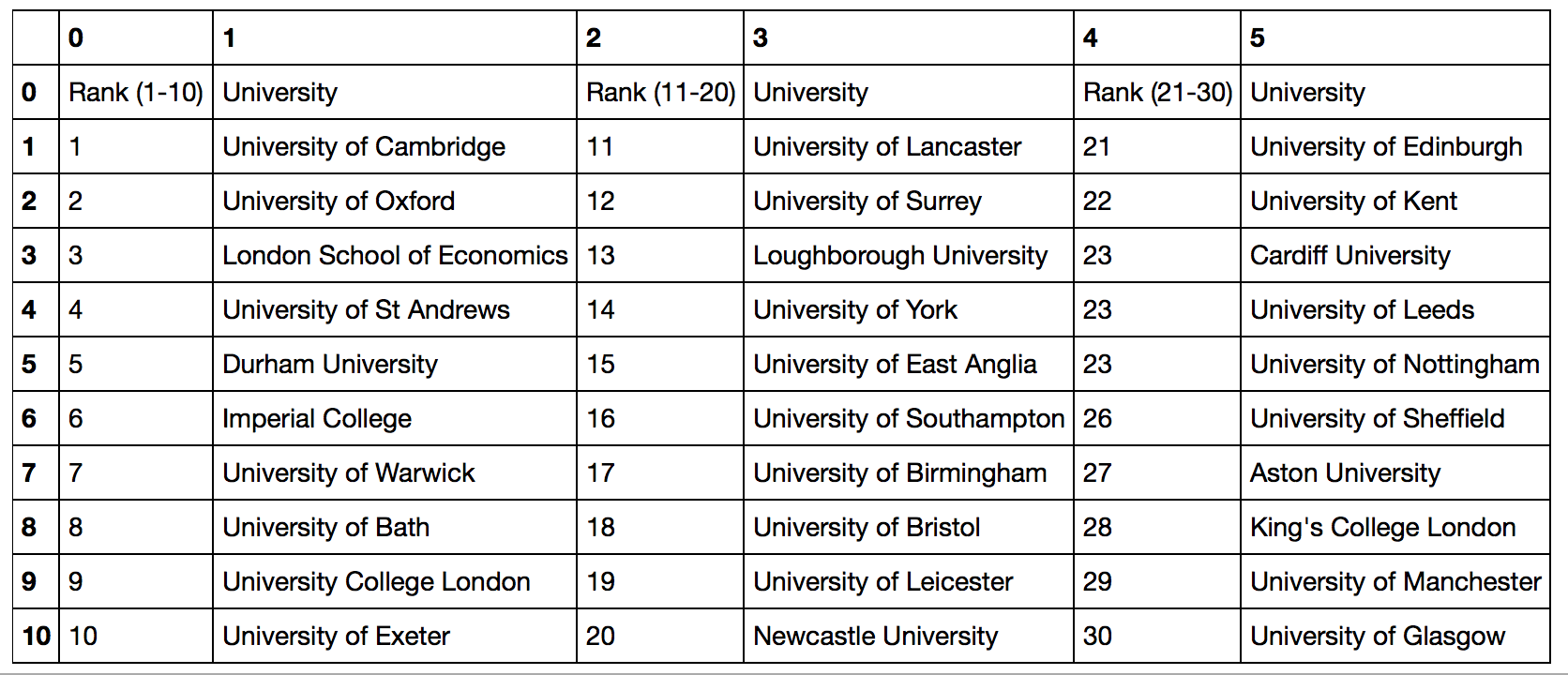
Immagine 1
In questo breve articolo esamineremo i passaggi necessari per importare un file .csv in pandas e le relative possibilità di personalizzazione.
Importare il file
I file .csv (“comma separated values”) sono file che contengono valori separati tra loro da caratteri (di default si tratta di virgole). Pandas dispone di un comando adatto ad importare direttamente i dati contenuti in questo tipo di file.
Prima di tutto, procediamo ad importare la stessa libreria pandas all’inizio dello script che stiamo scrivendo in Python. Per brevità, decideremo di importare pandas usando l’alias pd.
import pandas as pd
Chiaramente, qualora non avessimo installato pandas sul nostro computer, eseguendo questa riga di codice si andrà incontro ad un errore. Per il momento, ipotizziamo di aver già eseguito quanto spiegato qui, e procediamo. É arrivato il momento di importare il nostro file .csv!
dati = pd.read_csv('file.csv')
In questo caso stiamo riproducendo una situazione ideale: il file da importare si trova nella stessa cartella dove abbiamo salvato il nostro script. Come facciamo a recuperare dati salvati da un’altra parte? Non ci resta che specificare il path:
dati = pd.read_csv(r'C:\User\path\file.csv')
Questo è quello che occorre per importare un file .csv indipendentemente da dove esso sia. Probabilmente mi chiederai: “Tutto qui”?. Sì e no. Il comando read_csv() prevede degli argomenti supplementari che possiamo utilizzare o meno, secondo i nostri gusti e le nostre esigenze.
Specificare il separatore: sep o delimiter
Il separatore di default di read_csv() è la semplice virgola. Tuttavia, se il nostro file .csv usa un altro separatore (ad esempio il punto e virgola o uno spazio) ci basterà specificarlo. Chiaramente, per essere quanto più chiari possibile, si può anche specificare la virgola come carattere che separa i valori, nonostante la ridondanza di tale accorgimento.
dati = pd.read_csv(r'C:\User\path\file.csv', sep = ',') dati = pd.read_csv(r'C:\User\path\file.csv', sep = ';') dati = pd.read_csv(r'C:\User\path\file.csv', sep = ' ') dati = pd.read_csv(r'C:\User\path\file.csv', delimiter = ',') dati = pd.read_csv(r'C:\User\path\file.csv', delimiter = ';') dati = pd.read_csv(r'C:\User\path\file.csv', delimiter = ' ')
N.B. “sep” e “delimiter” sono sinonimi. Data la brevità del primo, personalmente lo preferisco.
Specificare il separatore quando a separare i valori sono degli spazi
Nel paragrafo precedente abbiamo visto come si fa ad indicare quando il carattere che separa i valori è uno spazio bianco. In realtà, gli argomenti:
sep = ' ' delimiter = ' '
fanno esattamente quello e sono utili se si tratta davvero di un solo spazio bianco. Cosa accade se per qualche ragione sono due o più spazi a separare i valori nel nostro file .csv? O se si tratta di tabulazioni? In tal caso, puoi usare questo argomento:
dati = pd.read_csv(r'C:\User\path\file.csv', delim_whitespace = True)
delim_whitespace si applica a qualsiasi spazio bianco, sia esso multiplo, una tabulazione ecc. Questo argomento funziona con valori booleani (True o False). Il valore di default è False. Quindi, a meno che non si vada a specificare che a separare il valori nel nostro file .csv siano degli spazi, questo argomento non sarà valido.
Specificare la riga di intestazione: header
A volte può capitare di voler specificare quale riga del file .csv andrà a costituire l’intestazione del nostro dataframe. In questo caso, non ci resta che includere l’argomento corrispondente nel comando di importazione del file .csv.
dati = pd.read_csv(r'C:\User\path\file.csv', sep = ',', header = 0)
In questo caso stiamo specificando che la prima riga del file .csv costituisce l’intestazione del dataframe (in Python si conta a partire da 0). L’argomento header ha zero come valore di default, quindi in questo caso avremmo potuto ometterlo. Ipotizziamo allora che vogliamo prendere la seconda riga del file .csv come intestazione. Il nostro codice avrà questo aspetto:
dati = pd.read_csv(r'C:\User\path\file.csv', sep = ',', header = 1)
Specificare la colonna che sarà l’indice del dataframe: index
Immaginiamo di avere un file .csv con due colonne, la prima con il nome di alcuni stati degli USA e la seconda con il rispettivo numero di abitanti. Importiamo questo file lasciando la prima colonna come intestazione, come da default:

Immagine 2
Come possiamo osservare, una colonna che funge da indice è stata aggiunta automaticamente al nostro dataframe. Ciò significa che tutti i dati del file importato vengono considerati come modificabili e facenti parte del nostro set. Immaginiamo però di volere che sia la colonna con il nome degli stati ad essere l’indice del dataframe. Come facciamo? Semplice, specifichiamo l’argomento corrispondente! Abbiamo due alternative:
dati = pd.read_csv(r'C:\User\path\file.csv', index_col = 0) dati = pd.read_csv(r'C:\User\path\file.csv', index_col = ['Stato'])
Con la prima, indichiamo che la prima colonna sarà l’indice; con la seconda lo facciamo specificando il nome della colonna, a prescindere dalla sua posizione nel file .csv. In entrambi i casi avremo raggiunto il nostro obiettivo e il dataframe avrà questo aspetto:

Immagine 3
Perché a volte è utile cambiare l’indice di un dataframe? Questo argomento viene approfondito in questo articolo.
Scegliere le colonne da importare: usecols
Immaginiamo di lavorare con il dataframe che abbiamo già osservato nell’Immagine 2. Come facciamo a importare in pandas solo alcune colonne? In questo caso ci basterà utilizzare un l’argomento usecols. Ciò ci permette di indicare le colonne del nostro set di dati che vogliamo utilizzare. Le altre, saranno automaticamente escluse dall’importazione.
dati = pd.read_csv(r'C:\User\path\file.csv', usecols = [0]) dati = pd.read_csv(r'C:\User\path\file.csv', usecols = ['Stato'])
Come abbiamo visto, possiamo specificare la colonna (o le colonne) da importare indicando il loro nome o il numero che indica la loro posizione nel dataframe. In entrambi i casi, il risultato sarà il seguente:
Immagine 4
Qualora le colonne che desideriamo importare siano più di una, possiamo tranquillamente specificare una lista di nomi o di numeri, come nell’esempio:
dati = pd.read_csv(r'C:\User\path\file.csv', usecols = [0,1]) dati = pd.read_csv(r'C:\User\path\file.csv', usecols = ['Stato','Popolazione'])
Qualora non specificato, l’argomento usecols ha come comportamento di default quell'o di importare tutte le colonne di un dataframe.
Specificare delle righe da escludere: skiprows
A volte capita che i il nostro file .csv contenga delle righe che non fanno parte del nostro set di dati. In questo esempio vediamo che il file .csv ha un titolo e l’indicazione della fonte subito prima i nostri tanto agognati dati.
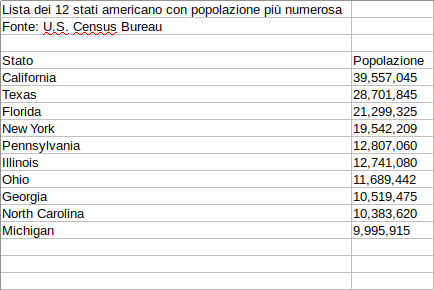
Immagine 5
Non ci resta che utilizzare l’argomento skiprows per specificare le righe del file da ignorare durante l’import. In questo caso vogliamo saltarne ben tre, così che il nostro dataframe incominci alla riga dove troviamo i nomi delle colonne. Ecco come fare:
dati = pd.read_csv(r'C:\User\path\file.csv', skiprows = 3)
Conclusione
In questo breve articolo abbiamo scoperto i 5 argomenti essenziali del comando read_csv() che possono davvero semplificarci la vita. In realtà, queste operazioni possono essere svolte anche successivamente all’importazione dei dati in pandas. Tuttavia, farlo durante l’import renderà il nostro codice più pulito ed essenziale.
Se vuoi ricevere delle micro-lezioni di Python per l’analisi dei dati via email, dai un’occhiata a analiticas, o iscriviti qui sotto